Na zajęcia z systemów rozproszonych postanowiłem rozwinąć lekko swój projekt ray tracera, tworzony w zeszłym roku.
Projekt oparty został o bibliotekę QT w wersji 4.5. Komunikacja odbywa się za pomocą socketów TCP.
Architektura tego rozwiązania opiera się o 3 elementy:
Klient – program, w którym operuje użytkownik chcący wygenerować obraz metoda ray tracing.
Serwer zarządzający – który rozsyła części obrazu do generowania przez serwery robocze
Serwery robocze – pracujące nad generowaniem poszczególnych części obrazu.
Jak to bywa w projektach studenckich, także i ten jest napisany obecnie dość chaotycznie i zawiera na pewno wiele błędów. Będą one jednak usuwane z biegiem czasu, a w chwili obecnej istotne jest raczej to, że projekt mniej więcej działa 🙂
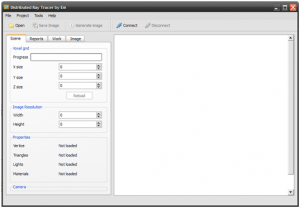
Na początek jeden screen klienta:
Na początek taki szkolny przykład dodawanie do siebie dwóch tablic wektorów.
Dodawanie kolejnych par wektorów odbywa się na karcie graficznej. Odpowiada za to funkcja vecAdd z kwalifikatorem global.
Kwalifikator ten oznacza, że funkcja może być wykonywana zarówno jako host (CPU) jak i device (GPU).
Prosty kod odpowiadający za dodawanie 2 wektorów
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
#include <stdio.h>
#include <cutil.h>
__global__ void vecAdd (float3 a[10], float3 b[10]) {
int i = threadIdx.x;
a[i].x += b[i].x;
a[i].y += b[i].y;
a[i].z += b[i].z;
}
int main(int argc, char** argv) {
CUT_DEVICE_INIT(argc, argv); // inicjalizacja GPU
float3 *a_h, *b_h, *a_d, *b_d, *result;
int arraySize = 10;
int sizeInBytes = arraySize * sizeof(float3);
a_h = (float3*)malloc(sizeInBytes); // inicjalizacja tablic (na hoscie)
b_h = (float3*)malloc(sizeInBytes);
result = (float3*)malloc(sizeInBytes);
CUDA_SAFE_CALL(cudaMalloc((void**)&a_d, sizeInBytes)); // inicjalizacja tablic na GPU
CUDA_SAFE_CALL(cudaMalloc((void**)&b_d, sizeInBytes));
for(int i = 0; i < arraySize; i++) { // przykładowe dane
a_h[i].x = 100.0f + i;
a_h[i].y = 200.0f + i;
a_h[i].z = 300.0f + i;
b_h[i].x = 50.0f + i;
b_h[i].y = 50.0f + i;
b_h[i].z = 50.0f + i;
CUDA_SAFE_CALL(cudaMemcpy(a_d, a_h, sizeInBytes, cudaMemcpyHostToDevice));
// kopiujemy tablicę z hosta do GPU
CUDA_SAFE_CALL(cudaMemcpy(b_d, b_h, sizeInBytes, cudaMemcpyHostToDevice));
vecAdd<<<1, arraySize>>>(a_d, b_d); // wykonujemy dodawanie
CUDA_SAFE_CALL(cudaMemcpy(result, a_d, sizeInBytes, cudaMemcpyDeviceToHost));
// kopiujemy z powrotem
for(int i = 0; i < arraySize; i++){
printf("Wartość %d.elementu %f, %f, %f \n", i, result[i].x,
result[i].y, result[i].z); // wyswietlamy :)
}
CUT_EXIT(0, NULL); // koniec
}
|
Wydaje się proste :)
W przyszłości postaram się opisać po kolei wszystkie szczegóły.
Żeby zacząć zabawę, należy kupić zabawkę.
Postanowiłem zaopatrzyć się w sprzęt, który pozwoli w pełni wykorzystać technologię CUDA do obliczeń związanych z ray tracingiem. Zdecydowałem się na Asusa GTX260, który nie miał zbyt wygórowanej ceny, ale oferował to co misie lubią najbardziej, czyli dużo “thread proccessors”. Sprzęcik wygląda mniej więcej tak:

Jeżeli chodzi o mechanizm CUDA, początkowo (czego nie dotyczytałem wcześniej) okazało się, że funkcje global, device (czyli te uruchamiane na karcie graficznej), nie obsługują rekursji! Więc algorytm rekursywnych testów przecięć się nie sprawdzi. Może jednak uda się zaimplementować równoległe przeprowadzanie testów cieni, co w przypadku scen z dużą liczbą świateł, może dość mocno przyspieszyć generowanie obrazu.
W kolejnych postach postaram się zaprezentować przykładowe zastosowanie CUDA do szybkich obliczeń, a także powiedzieć coś więcej o samej technologii.